
Research on different machine learning (ML) has become incredibly popular during the past few decades. However, for some researchers not familiar with statistics, it might be difficult to understand how to evaluate the performance of ML models and compare them with each other. Here, we introduce the most common evaluation metrics used for the typical supervised ML tasks including binary, multi-class, and multi-label classification, regression, image segmentation, object detection, and information retrieval. We explain how to choose a suitable statistical test for comparing models, how to obtain enough values of the metric for testing, and how to perform the test and interpret its results. We also present a few practical examples about comparing convolutional neural networks used to classify X-rays with different lung infections and detect cancer tumors in positron emission tomography images.

Due to our developed technology and access to huge amounts of digitized data, the number of different applications using machine learning (ML) has increased dramatically during the past few decades 1 . Whereas ML techniques initially included only statistical methods and simple algorithms 2 , ML is currently used for different purposes across the fields of engineering, medicine, public health, finance, politics, and natural sciences, both in academia and industry 3 . However, because of this immerse interdisciplinary interest, some of the new ML researchers might not have a good grasp of basic statistical concepts. This prompts need for ongoing education about the proper use of statistics and appropriate metrics for evaluation of performance of ML algorithms.
When new ML models are created, it is necessary to compare their performance to the already existing ones 4 . Evaluation serves two purposes: methods that do not perform well can be discarded, and the ones that seem promising can be further optimized. Also, especially in medicine, it is often useful to know whether an ML model outperforms an educated professional or not 5,6,7 . In supervised ML, we first divide our data for training and test sets, use the training data for training and validation of the model, predict all the instances of the test data, and compare the obtained predictions to the corresponding ground-truth values of the test set 8 . In this way, we can estimate whether the predictions of a new ML model are better than the predictions of a human or existing models in our test set.
Despite complexity of final applications, ML models typically consists of relatively simple sub-tasks, such as binary or multi-class classification and regression. In addition, a special image processing ML technique called a convolutional neural network (CNN) can be used to perform image segmentation 9 and object detectors are used to find desired targets in images or video footage 10 . Depending on the task in question, there are certain choices of evaluation metrics that can be used to assess the performance of supervised ML models 11 . There are also established statistical testing practices, especially for metrics used in binary classification 8,12 . Nonetheless, the misuse of certain well-known tests, such as the paired t-test, is common 4 , and the required assumptions of the tests are often ignored 11 .
Our aim here is to introduce the most common metrics for binary and multi-class classification, regression, image segmentation, and object detection. We explain the basics of statistical testing and what tests should be used in different situations related to supervised ML. At the end, we also give three examples about comparing the performance of CNNs for classifying X-rays related to lung infections and performing image segmentation for positron emission tomography (PET) images.
In a binary classification task, the instances of data are typically predicted to be either positive or negative so that a positive label is interpreted as presence of illness, abnormality, or some other deviation while a negative instance does not differ from the baseline in this respect. Each predicted binary label has therefore four possible designations: a true positive (TP) is a correctly predicted positive outcome, a true negative (TN) is a correctly predicted negative outcome, a false positive (FP) is a negative instance predicted to be positive, and a false negative (FN) is a positive instance predicted to be negative 13 . A confusion matrix, here a \(2\times 2\) -matrix containing the counts of TP, TN, FP, and FN observations like Table 1, can be used to compute several metrics for the evaluation of the binary classifier.
Alternatively, if we have n predictions \(q_i\in (0,1]\) for binary labels \(p_i\in \\) , we can also compute their cross-entropy loss defined as
$$\beginThe cross-entropy loss is often used for training ML models as its values decrease as the differences between the predictions and the real binary labels diminish 24 .
If the classification task is separating n instances between \(k\ge 3\) different classes, we can present the results of the classifier by using a \(k\times k\) confusion matrix as in Table 2. Its element \(n_\) at the intersection of the ith and the jth column for \(i,j=1,\ldots ,k\) is the number of instances from the ith classified to the jth class. The evaluation of this matrix uses same metrics that we introduced for binary classification.
One of the possible evaluation metric for an image segmentation masks is accuracy. In case of binary segmentation, we could simply count the number of TP, TN, FN, and FP pixels and calculate the accuracy as in (1). However, the issue with this approach is that the number of positive pixels is typically very small compared to the number of negative pixels: For instance, if we try perform tumor segmentation for medical images of the body, the positive targets, while incredibly important, have minimal volume compared to the background and they might not even be present in some images. Because of this, the value of accuracy can be very high even in the cases where the model does not find the positive object as long as the majority of negative pixels is correct.
Consequently, the results of binary segmentation are often evaluated with a metric that ignores the TN points. Instead, we concentrate on evaluating the similarity of the predicted positive segment given by a CNN and the ground-truth positive segment annotated by a human. For this purpose, we can use the Sørensen–Dice similarity coefficient 30,31 , also known as the Dice score, defined for two sets X and Y as
$$\beginwhere |S| denotes the number of pixels or voxels in the set S 32 . This definition can be equivalently written as
$$\beginby using the elements of the confusion matrix from the binary predictions of the points 32 . A very similar alternative to Dice score is the Jaccard similarity coefficient 33 , which is also known as the Jaccard index or Intersection over Union (IoU), and defined as
$$\beginfor the sets X and Y, and
$$\beginfor the elements of the confusion matrix 32 . The equality \(\textrm=D/(2-D)\) holds trivially between the IoU and the Dice score 32 .
There are also metrics specially designed for 3D segmentation, as this is common task for medical tomography images. The surface of the point set X, denoted by \(\partial X\) , is the set of all voxels in X for which at least one of the 18 or the 26 neighbour voxels is does not belong in X. As an alternative to the typical Dice score, the surface Dice similarity coefficient (SDSC) can be computed by replacing X and Y with their surfaces \(\partial X\) and \(\partial Y\) in (5). Let d(x, y) be the Euclidean distance between two voxels x and y, and define \(d(x,Y)=\min _
The Hausdorff distance is \(\textrm(X,Y)=\max _
The results of multi-class semantic segmentation are typically evaluated by using mean Dice or IoU values, either as the mean of all within-class scores in a single image or the class-specific means of several images. The similarity of two semantic segmentation masks or any two can be also evaluated with structural similarity index measure (SSIM). If u and v are two image matrices with means \(\overline\) and \(\overline\) , variances \(s_u\) and \(s_v\) , and covariance \(s_\) , then we have
$$\beginfor constants \(c_1\) and \(c_2\) depending on pixel values 35 . The SSIM is typically computed by using the formula above within several kernels or windows of the images. The values of SSIM are interpreted as those correlation: 1 for perfect similarity, 0 for no association, and \(-1\) for perfect opposites.
Another similar tasks related to image processing is object detection, in which we find bounding boxes around each object in the image and classify them into different classes. A good object detector is capable of finding all the objects in an image without producing any false observations, placing the bounding boxes as close their correct locations as possible, and also classifying all the found objects correctly. Due to the diversity in these subtasks, evaluation of object detectors is slightly more complicated than it is for the other models introduced.
To evaluate the results of object detection, we must start by counting how many objects of a specific class were found. This quickly leads to the question how to decide how close a predicted bounding box needs to be a ground-truth box so that we can interpret the object as found. The common criteria here is IoU defined as in (6): The prediction is only considered a match of a ground-truth box if the IoU value of the two boxes exceeds a certain threshold value, often 0.5. If there are several predicted boxes producing an IoU high enough with the same ground-truth box, only the best one in terms of IoU is considered a match to the ground-truth box while all the others are FP observations. Namely, FP is here the number of predicted boxes without a matching ground-truth box while TP is the number of the predictions that match a ground-truth box of the same class and FN is the number of ground-truth boxes without a matching prediction 10 .
With the TP, FP, and FN numbers of the specific class, we can compute precision and recall as in (1). Since an object detector outputs a confidence for every bounding box expressing how confident the model is about the prediction, we can remove the predictions below a threshold of confidence. Changing this threshold affects TP, FP, and FN numbers and therefore also precision and recall. The precision-recall curve (PRC) can be obtained by plotting precision against recall at all possible thresholds of confidence. After that, we can compute average precision (AP) as the area under the PRC. The whole model is evaluated by computing mean average precision (mAP) as the mean value of the APs in all the different classes. We often consider mAP@0.5 which is computed by using the IoU threshold 0.5 to define a match but just as well we could compute mAP@0.75 or mAP@0.9, or mAP@[0.5:0.95] which is the the mean value of mAP@0.5, mAP@0.55, \(\ldots\) , mAP@0.95. The metric mAP@0.9 is more strict than mAP@0.5 given it requires greater overlap for the potential matches and is therefore suitable for situations where the predicted bounding box locations need to be very exact 10 .
Information search and retrieval is a significant task in ML research. The ability to retrieve only relevant results from large image- or text-based databases is crucial for these databases to be actually useful. Search engines and other information retrievals models can be evaluated by using precision and recall to describe the percentage of relevant retrieved documents among either search results or all the relevant documents. If we have K results \(d_1,\ldots ,d_K\) ordered by estimated relevance from the database D and each document d is either relevant ( \(\textrm(d)=1\) ) or not ( \(\textrm(d)=0\) ), we can compute precision of the first k retrieved documents as P@ \(k=\sum ^k_\textrm(d_i)/k\) , for \(k=1,\ldots ,K\) and then define AP as 36
$$\beginThe mAP is obtained by a mean value of AP across different topics or search queries 36 . If results have more classes than just relevant and non-relevant, discounted cumulative gain (DCG) of k first results can be defined as
$$\beginwhere G(i) is a numerical value presenting the gain of the ith result 37 . For instance, the values 10, 7, 3, 0.5, and 0 are often used for perfect, excellent, good, fair, and bad results, respectively 37 . If there are several search queries to be evaluated, mean DCG can be used.
The motivation behind statistical tests is often to find out whether there is a significant difference between two different populations within respect of some specific property. We can collect smaller data sets from the populations and use them to compute values of the numeric quantity representing the feature of interest. Since there is nearly always at least slight difference between these values, the relevant question is whether this difference is great enough to be considered as an actual evidence of an underlying dissimilarity between the populations or if it is just a result of random variation.
The process of statistical testing is relatively simple: We formulate a null hypothesis \(H_0\) according to which there is no real difference, choose some level of significance \(\alpha \in (0,1)\) , and define a suitable test statistic Z with a known probability distribution \(P(Z|H_0)\) under the null hypothesis. We then use this distribution to compute the probability of obtaining at least as extreme value for the statistic Z than the one value z already observed. If the resulting probability \(p=2\min \
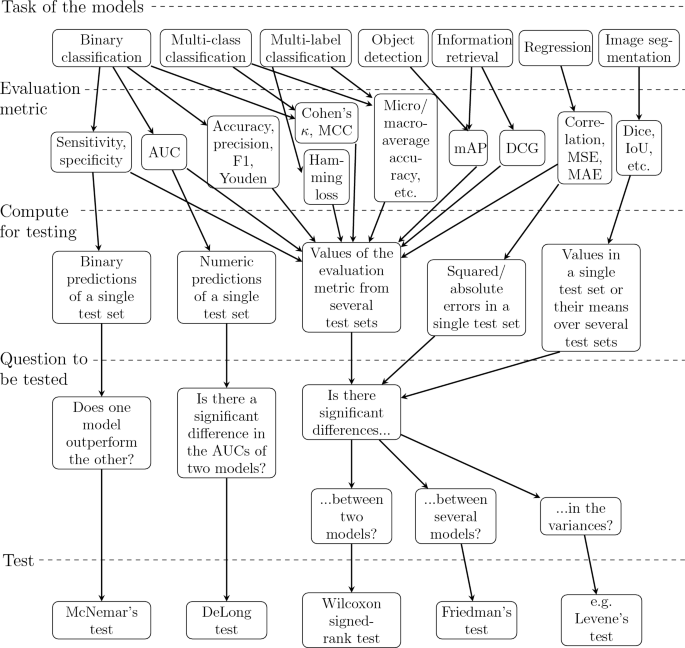
When comparing performance of two or more models, it is often necessary to perform the tests for multiple times depending on the evaluation metric and the statistical test used. For instance, while we can compute Dice score of every predicted segmentation mask in the test set, we only obtain one value of accuracy from the predictions of the whole test set after binary classification and as well as one value of MSE after regression. If we want to compare regression models, we can test squared errors instead of their mean and, in case of binary classification, there are tests that are based on the predictions of a single test set. In other cases, we have to evaluate our models on several test sets to obtain enough values from other evaluation metrics for statistical testing. The required values of an evaluation metric for a certain statistical test are summarized in the flowchart of Fig. 3.
While the test sets should ideally come from fully different data sets, sometimes our only option is to use a resampling procedure to create multiple test sets from the same data. In practice, we must re-initialize, train, and test the models for several times and save the values of the evaluation metrics from the predictions of the test set on each iteration round. We should use same training and test set for all the models on the same iteration round but vary them between the rounds because, otherwise, our conclusions about a potential difference between the models might be misled by some unknown factor in these specific data sets. Researchers commonly use here k-fold cross-validation, in which the data is divided into k similarly sized folds and, during k iteration rounds, each fold is the test set exactly once while the other \(k-1\) form the training data 12 . Alternatively, we can perform repeated cross-validation that has a few re-runs of each potential test set 12 . However, it should be taken into account that resampling methods do not produce independent values for the evaluation metrics and might lead to underestimating the variance of the test statistic, causing biased results 12 .
Regardless of whether the values of the evaluation metric come from a single test set or several test sets on different iteration rounds, the values of the metric for the two models are based on the same instances and therefore paired. Many researchers therefore check which of the models gives a higher mean and then use a paired t-test to test if the difference in the mean is significant 4 . The null hypothesis of the paired t-test is that the mean of the differences in the matched pairs is equal to 0 40 , and this test can be performed with the function ttest_rel in the package scipy.stats 41 in Python or t.test(x,y,paired=TRUE) in the base package stats in R. There are also such newer variations of the t-test that are specially designed to repeated cross-validation 11 . However, the t-test is not recommended for this situation because it is strongly affected by outliers 4 and not valid when resampled test sets are used 12 .
Another possible test is a sign test. If two models are evaluated by using N test sets and there is no difference between them, then each of them should produce a better value for the evaluation metric N/2 times 4 . Thus, the number of times where the first model is better than the second follows a binomial distribution and, for a greater number of N, a normal distribution with a mean N/2 and standard deviation \(\sqrt/2\) 11 . We can therefore apply the sign test to test whether one of the models outperforms the other with respect to the chosen evaluation metric in a statistically significant way. However, the sign test has a very weak power for detecting significant differences 4 .
The best alternative for this situation is the Wilcoxon signed-rank test instead 4 . It is a non-parametric test for the null hypothesis that the median of the differences in the matched pairs is equal to 0 42 . This test has the test statistic
and \(\textrm(|d_i|)\) , \(i=1,\ldots ,n\) , denote the differences \(d_i\) in the n matched pairs ranked by their absolute values 43 . The T-statistic can be examined directly by using its own critical values or, for large values of n, utilizing the statistic
$$\beginwhich follows the normal distribution under the null hypothesis 4 . The Wilcoxon signed-rank test can be performed with wilcoxon in scipy.stats in Python or wilcox.test(x,y, paired=TRUE) in stats in R.
As explained above, we can use Wilcoxon signed-rank test to estimate whether the differences between two models are significant with respect to any evaluation metric, but this test is not ideal when comparing several models. Namely, while we can repeat Wilcoxon tests between each pair of models, the risk of type I error increases with multiple comparisons. Adjusting the level of significance by Bonferroni correction has been suggested as a solution 44 but it is overly radical 4 .
Instead, the better approach in a situation where we have K models evaluated in J data sets is to perform Friedman’s test 4 . The average rank of the kth model, \(k=1,\ldots ,K\) , is \(\overline_k=\sum ^J_r^j_k/J\) where \(r^j_k\) is the rank of the jth value of the evaluation metric for the kth model 4 . The test statistic can be now written as
$$\beginor, as noted by Iman and Davenport 45 , as 4
$$\beginOut of the two statistics, \(\chi ^2_F\) is overly conservative and \(F_\) is therefore recommended 4 . Under the null hypothesis, \(\chi ^2_F\) follows the \(\chi ^2\) -distribution with \(K-1\) degrees of freedom and \(F_\) follows the F-distribution with \(K-1\) and \((K-1)(J-1)\) degrees of freedom 4 . Friedman’s test can be performed with friedmanchisquare in scipy.stats in Python or friedman.test in stats in R, but both of these functions are based on the statistic \(\chi ^2_F\) and therefore are not reliable for small values of J. However, if J is small, we can use a few separate Wilcoxon signed-rank tests instead.
There are also such tests for comparison of two classifiers which only require their predictions from a single iteration round. McNemar’s test is a common non-parametric test that only requires two numbers and is typically used to compare either sensitivity or specificity of two classifiers 46 . To find out whether there is a significant difference in the sensitivity of the classifiers, let b be the number of positive instances in the test set misclassified as FN by the first classifier but not by the second classifier and c similarly the number of positive instances misclassified as FN by the second classifier but not by the first classifier. To study specificity, count the numbers b and c by using FP misclassifications among the negative instances. Comparing accuracy by counting errors among both positive and negative sets is not recommended 47 . If there is no significant difference in the performance of the two classifiers, the test statistic
$$\beginfollows the \(\chi ^2\) -distribution with 1 degree of freedom for \(b+c\ge 20\) and a binomial distribution otherwise 11 . This test can be performed with mcnemar in statsmodels.stats.contingency_tables 48 in Python or mcnemar.test in stats in R.
We can also use the DeLong test to see whether there is a statistically significant different between the AUCs of two binary classifiers. Namely, DeLong et al. 49 noticed that the Mann-Whitney statistic can be used as an estimate of an AUC and the theory of generalized U-statistic can be applied to compare two AUCs. The Mann-Whitney two-sample statistic for AUC can be written as
where m is the number of truly positive instances, n is the number of the number of truly negative instances, \(Y_\) is the numeric prediction of the ith positive instance before it was converted into binary and, similarly, \(Y_\) is the numeric prediction of the jth negative instance 50 . Let \(\hat_1\) be the estimate above for the AUC of the first classifier and \(\hat_2\) the same for the second classifier. The DeLong test estimates their variance and covariance (see e.g. 51 for the exact formulas) and then uses the statistic
$$\beginwhich follows the normal distribution under the null hypothesis due to the properties of the known U-statistic 51 . The DeLong test can be performed with roc.test(x,y,method= ’delong’) in the package pROC 52 in R.
Another important factor when comparing the performance of models is the amount of variance they produce. A model that consistently obtains high values in some evaluation metric is better than a model whose performance varies greatly on different iteration rounds. However, it must be taken into careful consideration here how the multiple values of the evaluation metric are obtained before considering their variance. For instance, if we use repeated cross-validation, we will not obtain a realistic estimate how the performance of a model would vary over different data sets.
We can use the F-test of equality of variances to test the null hypothesis according to which two populations have equal variances. The test statistic is \(F=S^2_1/S^2_2\) where \(S^2_1\) and \(S^2_2\) are the sample variations in the values produced by the two models for the evaluation metric, and this F-statistic follows the F-distribution with \(n-1\) and \(n-1\) degrees of freedom under the null hypothesis 53 .
However, the use of the F-test is not recommend for non-normally distributed values and this is often the case when comparing evaluation metrics: For instance, if the model has a median accuracy of 90% but a high amount of variation between different test sets, it is likely that the distribution of accuracy is left-skewed as the accuracy is limited on [0, 1] by its definition. The normality can be tested here with the Shapiro–Wilk test 54 ( shapiro in the package scipy.stats and shapiro.test in the package stats in R). If the data is not normally distributed, the possible alternatives for the F-test include Barlett’s test 55 ( bartlett in scipy.stats in Python and bartlett.test in stats in R) and Levene’s test 56 ( levene in scipy.stats in Python and leveneTest in the package car 57 in R).
In ML research, it is often of interest if a specific ML model performs better than a human. Especially, in a medical field, it is useful to estimate the difference between the tumor masks predicted by a CNN differ and those drawn by a physician by taking into account how much difference there would be if the same masks were drawn by two different physicians. For this purpose, we can use statistical testing to compare the results of an ML model and a human in terms of a relevant evaluation metric as we would compare the performance of two models. However, there might be some cases where this comparison is not possible: A human is not able to go through very large amounts of data, at least not fast, and, while we can always re-initialize the model between different rounds of repeated cross-validation, a human will not forget their earlier decisions. Because of this, statistical comparison between an ML model and a human is often limited to using McNemar’s test or the DeLong test to compare classifications in a single test set or the Wilcoxon signed-rank test to compare segmentation masks in terms of Dice and IoU values for a reasonable number of images.
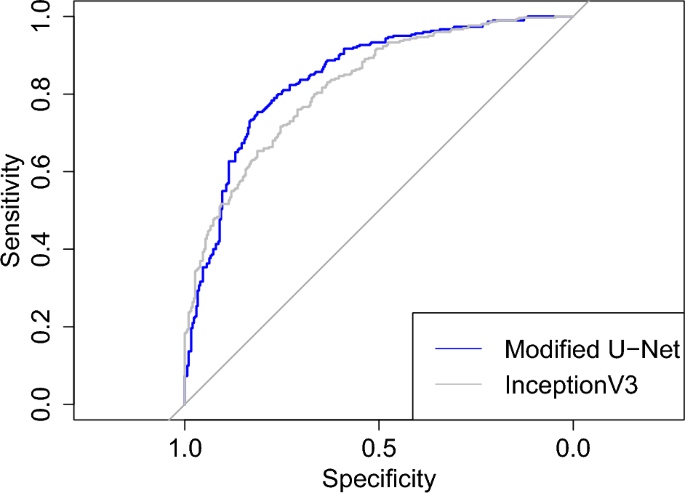
The CNNs were coded in Python (version: 3.9.9) 38 with packages TensorFlow (version: 2.7.0) 58 and Keras (version: 2.7.0) 59 . Most of the test were preformed in Python with scipy (version: 1.7.3) 41 or statsmodels (version: 0.14.0) 48 . The DeLong test was performed and Fig. 1 was plotted with pROC (version: 1.18.5) 52 in R (version: 3.4.1) 39 . The images of the third data set had been studied with Carimas (version: 2.10) 60 , which was also used to draw their binary masks.
We use three data sets consisting of two-dimensional grayscale images converted into the size of 128 \(\times\) 128 pixels. The first data set contains 3000 chest X-rays of COVID-19 patients and 3000 chest X-rays of healthy patients chosen from COVID-19 Radiography Database 61,62 . The second data set has 700 chest X-rays of healthy patients and 700 chest X-rays of COVID-19 patients from COVID-19 Radiography Database, 700 chest X-rays of patients with pneumonia from Chest X-Ray Images (Pneumonia) 63 , and 700 chest X-rays of tuberculosis patients from Tuberculosis (TB) Chest X-ray Database 64 . The third data set has a total of 962 two-dimensional transaxial image slices from the PET images of 89 head and neck squamous cell carcinoma patients. The patients were imaged with \(^\) F-fluorodeoxyglucose tracer in Turku PET Centre, Turku, Finland, during years 2014–2022. More details about the imaging can be found in 65,66 . Each of the slices has also a ground-truth binary segmentation mask showing pixels depicting cancerous tissue as positive and the rest as negative, and they were chosen so that they have at least 6 positive pixels. All the cancer patients were at least 18 years of age, gave informed consent to the research use of their data, and the research from their data was approved by Ethics Committee of the Hospital District of Southwest Finland. All research was performed in accordance with the Declaration of Helsinki.
In both binary and multi-class classification, we use a CNN that has U-Net architecture by Ronneberger et al. 67 modified for classification 65 and a ready-built CNN called InceptionV3 available in Keras. For binary segmentation, we use two U-Nets, a shallower of which has 64 as maximum dimensionality of a Conv2D layer and a deeper of which has 128. They were also used in 66,68 . We use stochastic gradient descent as an optimizer for the classification CNN and Adam for the segmentation CNNs. The classification CNNs are trained on 10 epochs and the segmentation CNNs on 50. The learning rate of 0.001 and, during training, 30% of the training data is used for validation. After training the CNNs for binary classification, we predict both training and test sets and use the threshold giving the maximal Youden’s index in the training set as a threshold for converting the numeric predictions of the test set into binary labels. We similarly convert the output after binary segmentation by using the threshold that produces the highest median Dice in the training set. For the multi-class classification, we obtain directly class labels by using the maximum elements of one-hot encoding.
We first compare the performance of the modified U-Net and InceptionV3 in binary classification by using our first data set of COVID-19 and negative X-rays with fivefold cross-validation. We compute all the possible evaluation metrics from our single test set and use McNemar’s test for sensitivity and specificity and DeLong test for AUC. Then we compare the modified U-Net and InceptionV3 in multi-class classification with repeated fivefold cross-validation (5 re-runs of each test set). We save the values of micro- and macro-average evaluation metrics after each round and use the Wilcoxon signed-rank test to estimate whether the differences in the resulting 25 values of each metric are significant or not. Even though the paired t-test should not be used for this, we perform it to see if its p values would be different from those of the Wilcoxon test. Finally, we divide our third data set patient-wise into train and test sets so that the test set has 191 slices (19.9% of the total data), and compare the two U-Nets for binary segmentation. We use the Shapiro–Wilk test to test the normality of Dice and IoU values of different segmentation masks, t-test and Wilcoxon test to estimate their differences, and F-test, Bartlett’s test and Levene’s test to check if there are significant differences in variances.
The results of the binary classification task are summarized in the contingency table of Table 3 and the resulting values of the evaluation metrics are in Table 4. According two McNemar’s test computed from Table 3 separately for sensitivity among COVID-19 patients and specificity negative patients, the modified U-Net produced significantly higher sensitivity (p value < 5.07e−5) but significantly lower specificity (p value < 0.0207). The ROC curves of the modified U-Net and InceptionV3 can be seen from Fig. 1 and, according the DeLong test, there is no significant difference in their AUC (p value = 0.137).
Table 3 The contingency tables for comparing the performance of the modified U-Net and InceptionV3 in binary classification among both COVID-19 and negative X-rays separately.
Table 4 The evaluation metrics computed for the modified U-Net and InceptionV3 from Table 3.The median values of the evaluation metrics are in Table 5 for the multi-class classification task. According to t-tests and Wilcoxon tests, the modified U-Net is significantly better than InceptionV3, regardless of which metric is used. The p value of the t-test for macro-average F1-score is 6.47e−4 and less than 2.38e−5 for all the other metrics and, similarly, the p value of the Wilcoxon test for macro-average F1-score is 0.00116 and less than 6.37e−5 for all the other metrics.
Table 5 The median values of the evaluation metrics computed for the modified U-Net and InceptionV3 during the rounds of the multi-class classification task with repeated fivefold cross-validation.
The median and standard deviation of Dice and IoU values computed for the two U-Nets in the segmentation task are in Table 6, as are the p values of Shapiro–Wilk tests, t-tests, Wilcoxon tests, F-tests, Bartlett’s tests, and Levene’s tests. Based on these p values, neither Dice nor IoU values are normally distributed, the deeper U-Net is significantly better in terms of both Dice and IoU values, and, while the deeper U-Net had higher standard deviation, this difference is only significant according to Levene’s test performed for the IoU values.
Table 6 Median and standard deviation of Dice and IoU values computed from the binary segmentation masks predicted by two U-Nets for 191 image slices of the test set.
In our first experiment, we used both McNemar’s test and the DeLong test to study two CNNs used for binary classification. Our results show that the choice of the threshold was not ideal for the modified U-Net as we obtained high sensitivity on the cost of the specificity. This also reveals one issue with McNemar’s test: It does not tell us which classifier is better if one of them has a significantly higher sensitivity but a significantly lower specificity. We would need to use some other thresholds to convert the output of the CNN into binary labels and then repeat McNemar’s tests in order to find out if the significant differences are caused by specific threshold choices or not. In this respect, the DeLong test is more useful as its results do not depend on the threshold choices. However, to obtain more trustworthy results, it would still be necessary to use cross-validation and compare the AUCs of different test sets with the Wilcoxon signed-rank test.
In our second and third experiments, we used the t-test for comparing the values of evaluation metrics, even though it is not recommend for this, especially not when combined with repeated cross-validation. Its p values were relatively close to those of the Wilcoxon tests and, regardless of which test was used, we obtained the same conclusions about the significant differences. Since the misuse of the t-test is rather common, as noted by Demšar 4 , it is good to know that the results obtained in earlier research are not necessary wrong. Similarly, even though the F-test is not designed for non-normally distributed data, its p values were very close to those of Bartlett’s tests. However, both the t-test and the F-test are sensitive to the error caused by potential outliers so their use can lead incorrect results.
It should be noted here that aim of our experiments was to give examples of the use of the evaluation metrics and the related tests. To find out how often the t-test or some other test produces false conclusions when improperly used, more research is needed. Similarly, one possible topic for future research is also how many the number of the test sets affects the trustworthiness of the conclusions.
In this paper, we introduced several evaluation metrics for common ML tasks including binary and multi-class classification, regression, image segmentation, and object detection. Statistical testing can be used to estimate whether the different values in these metrics between two or more models are caused by actual differences between the models. The choice of the exact test depends the task of the models, the evaluation metric used, and the number of test sets available. As some metrics produce only one value from a single test set and there might be only one data set, some type of resampling, such as repeated cross-validation, is often necessary. Because of this, the well-known tests such the paired t-test underestimate variance and do not produce reliable results. Instead, the use of non-parametric tests such as the Wilcoxon signed-rank test or Friedman’s test is recommend.
Available at github.com/rklen/statistical_tests_for_CNNs.
We are grateful to the referees for their suggestions.